Architecture
Jaeger can be deployed either as an all-in-one binary, where all Jaeger backend components run in a single process, or as a scalable distributed system. There are two main deployment options discussed below.
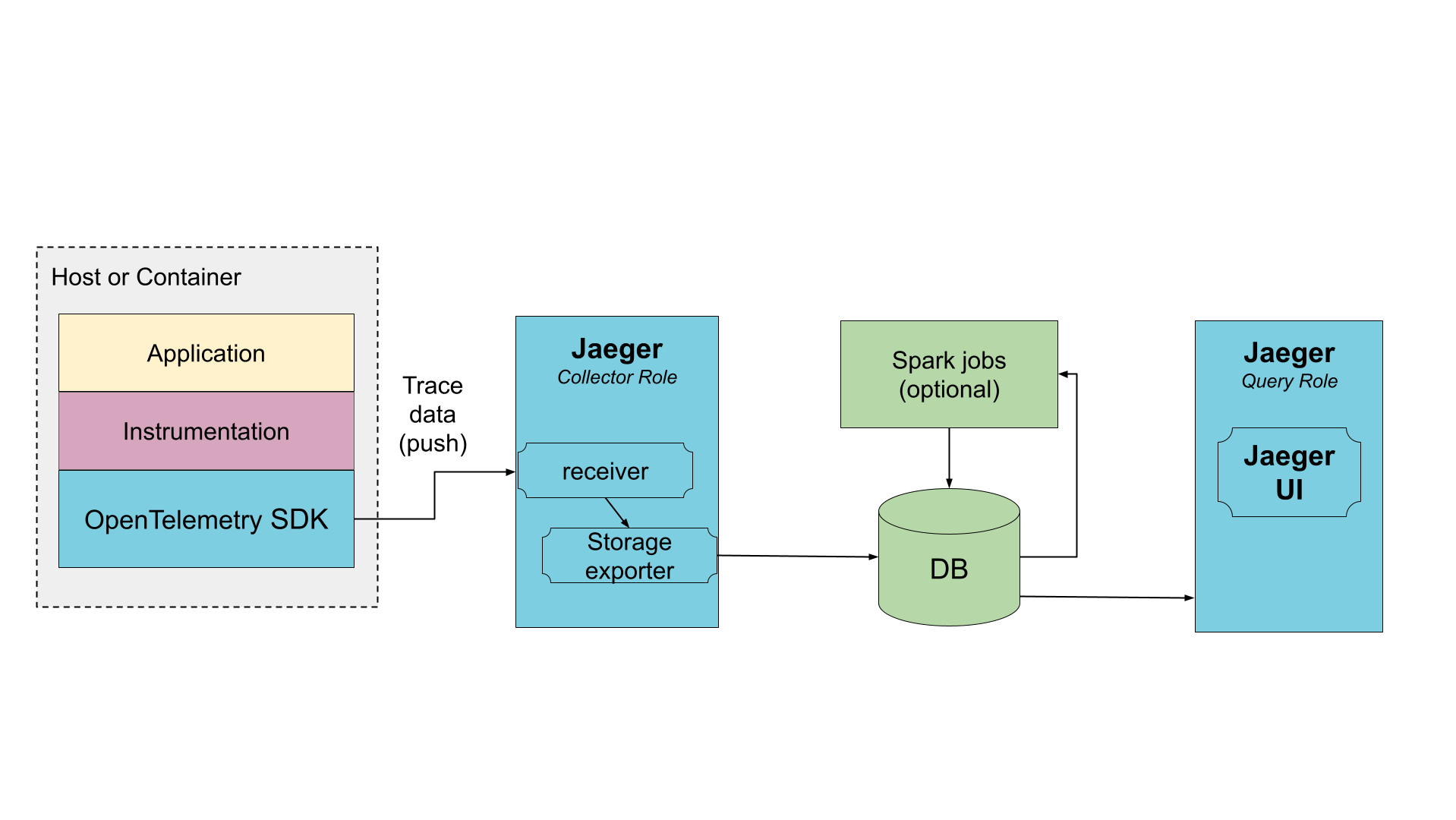
Direct to storage
In this deployment Jaeger receives the data from traced applications and writes it directly to storage. The storage must be able to handle both average and peak traffic. Collectors use an in-memory queue to smooth short-term traffic peaks, but a sustained traffic spike may result in dropped data if the storage is not able to keep up.
Via Kafka
To prevent data loss between collectors and storage, Kafka can be used as an intermediary, persistent queue. Jaeger can be deployed with OpenTelemetry to handle writing the data to Kafka and pulling it off the queue and writing the data to the storage. Multiple Jaeger instances can be deployed to scale up ingestion; they will automatically partition the load across them.
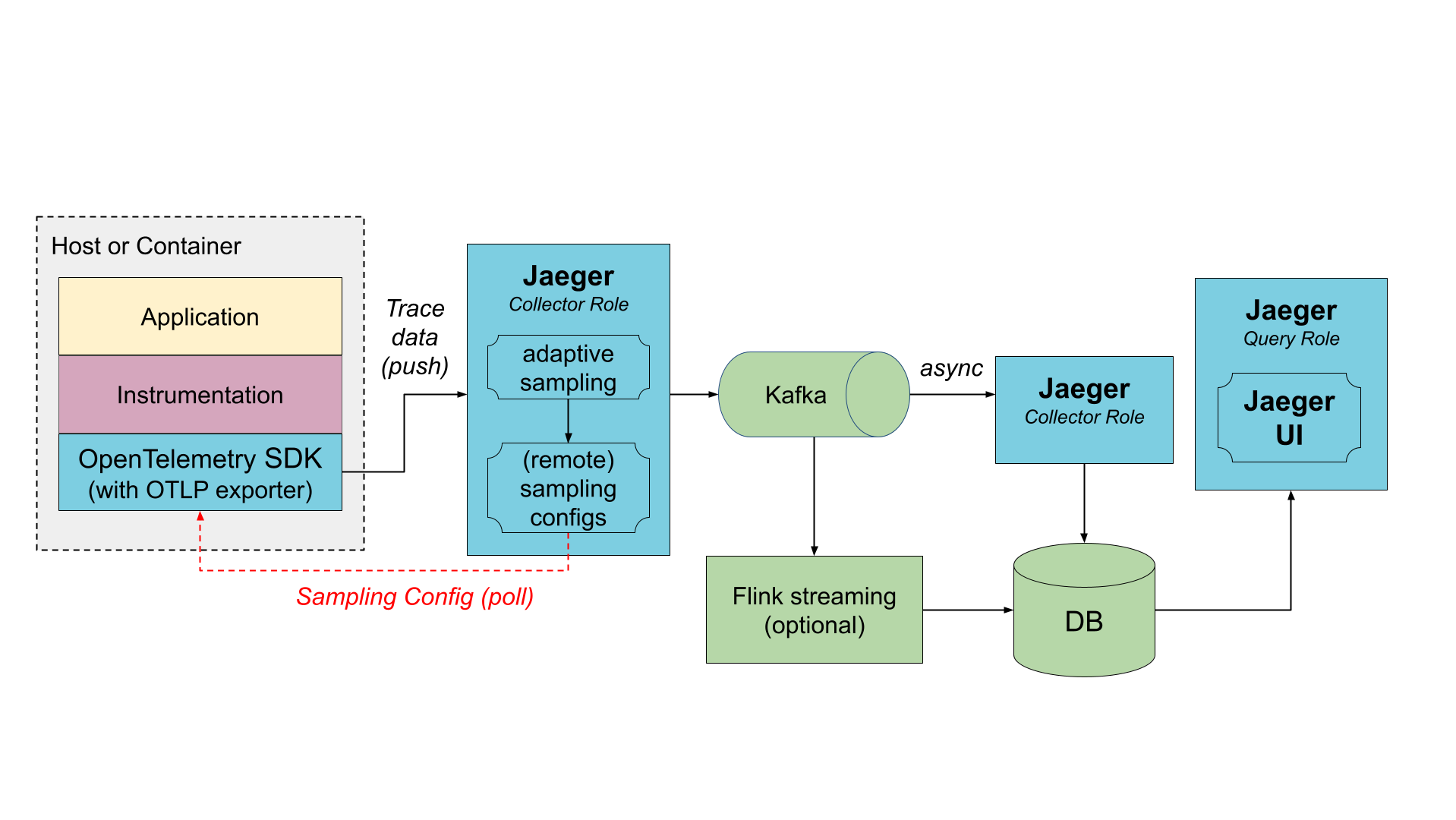
With OpenTelemetry Collector
You do not need to use OpenTelemetry Collector, because Jaeger is a customized distribution of the OpenTelemetry Collector with different roles. However, if you already use the OpenTelemetry Collectors, for gathering other types of telemetry or for pre-processing / enriching the tracing data, it can be placed before Jaeger. The OpenTelemetry Collectors can be run as an application sidecar, as a host agent / daemon, or as a central cluster.
The OpenTelemetry Collector supports Jaeger’s Remote Sampling protocol and can either serve static configurations from config files directly, or proxy the requests to the Jaeger backend (e.g., when using adaptive sampling).
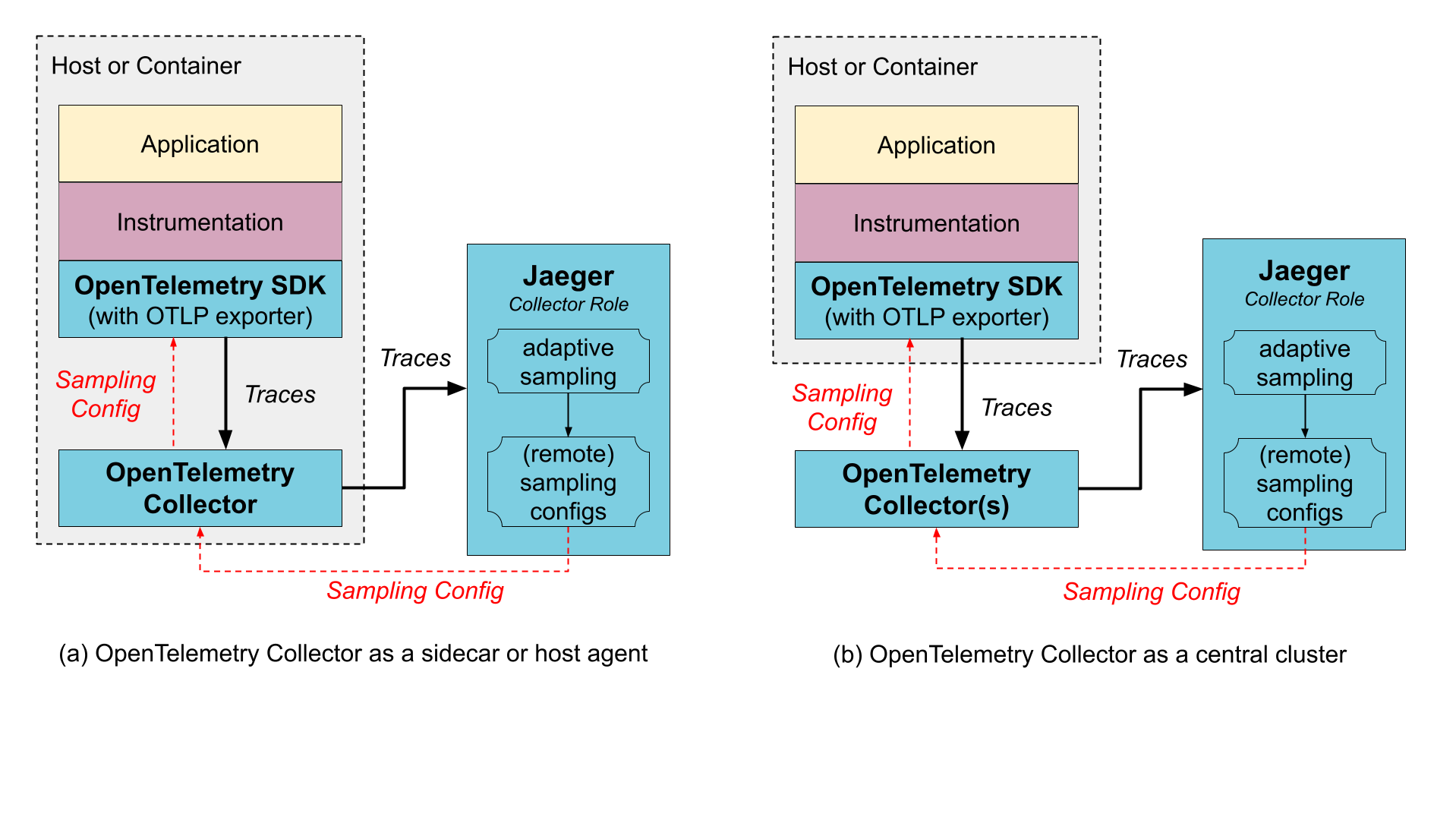
OpenTelemetry Collector as a sidecar / host agent
Benefits:
- The SDK configuration is simplified as both trace export endpoint and sampling config endpoint can point to a local host and not worry about discovering where those services run remotely.
- Collector may provide data enrichment by adding environment information, like k8s pod name.
- Resource usage for data enrichment can be distributed across all application hosts.
Downsides:
- An extra layer of marshaling/unmarshaling the data.
OpenTelemetry Collector as a remote cluster
Benefits:
- Sharding capabilities, e.g., when using tail-based sampling.
Downsides:
- An extra layer of marshaling/unmarshaling the data.
